Par Elisha Bajemon, Ingénieur IA chez TW3 Partners. Dernière mise à jour : 27 mai 2026.
En 2026, miser sur un seul grand modèle de langage (LLM) pour un système d’IA en production revient à confier toute une chaîne logistique à un unique transporteur : cela fonctionne tant que rien ne casse. Une hausse tarifaire, un changement de conditions, une dégradation de performances ou une indisponibilité expose immédiatement l’organisation. Racine.AI, l’architecture conçue par TW3 Partners, part d’un constat industriel simple : une architecture multi-LLM hybride combinant modèles propriétaires et modèles ouverts, orchestrée par un routeur intelligent et adossée à une base de connaissances souveraine, est aujourd’hui l’une des approches les plus robustes pour combiner qualité, coûts maîtrisés, gouvernance et indépendance technologique.
Réponse courte (factuel)
Une architecture multi-LLM hybride expose plusieurs modèles (propriétaires et à poids ouverts) derrière une couche unique d’orchestration. Un routeur sélectionne, pour chaque requête, le modèle le mieux adapté selon quatre critères : qualité attendue, coût, latence, résidence des données. Cette approche est documentée par les principaux observateurs du secteur (Stanford HAI, McKinsey, Hugging Face) et alignée avec les exigences croissantes de gouvernance, traçabilité, continuité et maîtrise des risques posées par le cadre européen (AI Act, NIS2, ISO/IEC 42001, NIST AI RMF, SecNumCloud).
Réponse courte (démo TW3)
TW3 Partners présente Racine.AI sur le stand Hall 7.2, Allée C, Stand 74 lors de VivaTech 2026, du 17 au 20 juin 2026. La démonstration couvre le routage multi-LLM en direct, la base vectorielle souveraine et le benchmarking GEO via DataGeo (tw3partners.fr).
Sommaire
Pourquoi le multi-LLM s’impose en 2026
Les trois composants de Racine.AI et l’observabilité transverse
Bénéfices structurels visés
Quatre cas d’usage représentatifs
Positionnement modèles ouverts et souveraineté
Méthode TW3 et démonstration VivaTech 2026
FAQ étendue
Sources
1. Pourquoi le multi-LLM s’impose en 2026
Quatre constats convergents, étayés par les rapports de référence du secteur, justifient le passage d’une architecture mono-modèle à une architecture multi-LLM.
1.1 Aucun modèle universel n’existe
Le Stanford HAI AI Index 2025 documente la convergence des performances entre modèles propriétaires et modèles à poids ouverts sur les principaux benchmarks (MMLU, HumanEval, GPQA, MATH, SWE-bench). Sur le Hugging Face Open LLM Leaderboard, des modèles ouverts dépassent certains modèles propriétaires sur des tâches précises (raisonnement multi-étapes, génération de code, instruction following multilingue). Côté propriétaire, les principales familles sont ChatGPT (OpenAI), Claude (Anthropic), Gemini (Google), Copilot (Microsoft) ; côté poids disponibles, Mistral (Large, Small, Codestral), Llama (Meta), Phi (Microsoft), Qwen (Alibaba) et DeepSeek (séries V3 et V3.2).
Aucun modèle généraliste ne couvre simultanément le raisonnement long, la rédaction nuancée, la génération de code, l’extraction structurée et le multilingue avec la même qualité. Sur le code, Codestral, Qwen 2.5 Coder et les modèles DeepSeek figurent parmi les modèles spécialisés les plus compétitifs ou les plus utilisés selon les benchmarks publics (SWE-bench, LiveBench, HumanEval) et les retours développeurs.
1.2 Un rapport coût-performance qui varie de plusieurs dizaines de fois
Le coût par million de tokens varie de plusieurs ordres de grandeur entre modèles. Entre un modèle haut de gamme propriétaire et un petit modèle ouvert quantifié servi via vLLM ou Ollama sur infrastructure dédiée, le rapport coût-performance peut varier de plusieurs dizaines de fois selon le modèle, le mode de déploiement et le volume ; sur certaines configurations tarifaires publiques, l’écart atteint un facteur 75. Pour un volume important de requêtes simples (extraction, classification, reformulation courte), la qualité d’un modèle 7B à 14B est largement suffisante. McKinsey State of AI 2024 confirme que les organisations matures en IA générative dégagent leur ROI principalement par l’optimisation du couple modèle-tâche, pas par l’usage du modèle le plus puissant pour tout.
1.3 Gouvernance des données et cadre réglementaire européen
Le règlement UE 2024/1689 (AI Act) est entré en vigueur le 1er août 2024. Les obligations applicables aux modèles d’IA à usage général (GPAI) sont exigibles depuis le 2 août 2025. Les obligations relatives aux systèmes à haut risque s’appliquent progressivement : jalon majeur au 2 août 2026 pour les systèmes de l’Annexe III et les règles de transparence de l’article 50, avec des délais étendus jusqu’au 2 août 2027 voire au-delà pour certains systèmes intégrés à des produits déjà soumis à une réglementation sectorielle. Tous les systèmes haut risque n’entrent donc pas uniformément en application à la même date.
Les sanctions de l’article 99 sont graduées : jusqu’à 35 M€ ou 7 % du chiffre d’affaires mondial annuel pour les pratiques interdites (article 5) ; jusqu’à 15 M€ ou 3 % pour les manquements aux obligations des opérateurs et organismes notifiés ; jusqu’à 7,5 M€ ou 1 % pour la fourniture d’informations incorrectes, incomplètes ou trompeuses.
S’ajoutent la directive NIS2 (cybersécurité des entités essentielles et importantes), ISO/IEC 42001 (système de management de l’IA), le NIST AI Risk Management Framework 1.0 et son profil GenAI (NIST AI 600-1), et le visa SecNumCloud de l’ANSSI pour les hébergements de données sensibles non classifiées. Une architecture mono-modèle hébergée hors UE est aujourd’hui difficilement compatible avec les exigences de résidence applicables au secteur public, à la défense, à la santé, à la banque et à plusieurs segments industriels.
1.4 Redondance et continuité d’activité
Indisponibilités, dégradations silencieuses et changements unilatéraux de conditions tarifaires des fournisseurs propriétaires sont devenus structurels. Une architecture multi-LLM permet, via le routeur, un basculement automatique vers un modèle de repli dans le respect d’un budget qualité et d’une politique de résidence, en ligne avec les principes de continuité d’activité retenus par NIS2 et reflétés dans les contrôles ISO/IEC 42001.
2. Les trois composants de Racine.AI
Racine.AI repose sur trois briques indépendantes mais interopérables, complétées par une couche transverse d’observabilité.
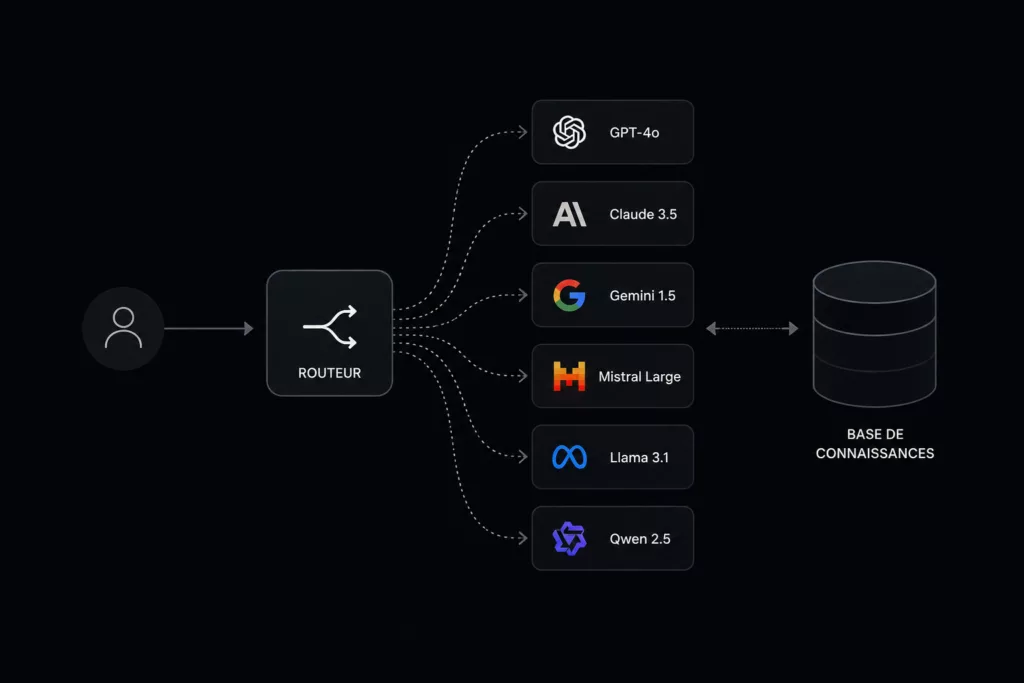
2.1 Catalogue de modèles
Le catalogue expose, derrière une API homogène, les modèles utilisables : propriétaires (ChatGPT, Claude, Gemini, Copilot), à poids disponibles (Mistral Large/Small/Codestral, Llama, Phi, Qwen, DeepSeek), et spécialisés code (Codestral, Qwen 2.5 Coder, DeepSeek V3/V3.2). Chaque entrée est décrite par un profil structuré : fenêtre de contexte, latence p50/p95, coût par million de tokens, capacités (tool calling, JSON mode, vision, raisonnement long), licence, juridiction d’hébergement, classification AI Act (GPAI standard ou à risque systémique).
L’écosystème européen structurant ce catalogue inclut notamment Mistral AI, qui a levé 600 M€ en juin 2024 (valorisation d’environ 5,8 Md€) puis une Série C de 1,7 Md€ en septembre 2025 menée par ASML (valorisation d’environ 11,7 Md€, premier décacorne IA français) ; et Hugging Face, fondée par Clément Delangue, Julien Chaumond et Thomas Wolf, présente à New York et Paris, qui a levé 235 M$ en Série D en août 2023 à une valorisation de 4,5 Md$.
L’auditabilité varie selon les licences, la documentation publiée et la transparence sur les données d’entraînement : aucun modèle n’est qualifié d’« open source » dans le catalogue sans vérification effective de sa licence et de la disponibilité de ses artefacts.
2.2 Routeur intelligent
Le routeur est le composant central. Pour chaque requête, il évalue un profil de tâche reconstruit à partir du prompt, du contexte applicatif et des métadonnées (utilisateur, sensibilité, juridiction), puis sélectionne un modèle en optimisant simultanément quatre critères : qualité attendue (score historique sur des tâches similaires), coût (prix au token, budget de la requête, budget mensuel du tenant), latence (SLA cible, p50/p95 glissants) et souveraineté (résidence des données, juridiction du fournisseur, classification réglementaire). Il applique un repli (fallback) déterministe en cas d’indisponibilité, dans le respect de la politique de souveraineté. Toute décision est journalisée et auditable.
2.3 Base de connaissances
La couche RAG (Retrieval-Augmented Generation) s’appuie sur une base vectorielle souveraine. Trois moteurs open source sont supportés : pgvector (extension PostgreSQL) pour les déploiements consolidés avec une base relationnelle existante, Qdrant pour les charges vectorielles intensives avec filtrage métadonnées avancé, et Weaviate pour les schémas hybrides texte plus structuré. L’orchestration applicative repose sur LangChain ou LlamaIndex selon la complexité des chaînes (agents, multi-step retrieval, outils).
2.4 Observabilité transverse
Chaque appel LLM produit une trace structurée : modèle sélectionné, justification de routage, prompt et contexte (anonymisés), tokens entrée/sortie, latence, coût, score qualité estimé, juridiction d’exécution. Cette télémétrie est exposée via Langfuse (prompts, sessions, évaluations), Phoenix Arize (détection de dérives, évaluation continue) et OpenTelemetry (intégration aux stacks existantes type Prometheus, Grafana, ELK, Datadog). Ces outils ne rendent pas automatiquement une architecture conforme : ils facilitent la traçabilité, l’évaluation continue et la production de preuves d’audit attendues par un évaluateur AI Act, ISO/IEC 42001 ou NIS2.
3. Bénéfices structurels visés
Les premiers retours d’architecture multi-LLM de type Racine.AI font ressortir quatre bénéfices structurels.
Réduction des coûts d’inférence. Affecter les tâches simples à de petits modèles ouverts servis via vLLM et réserver les modèles haut de gamme aux requêtes complexes permet de diminuer significativement la facture LLM sans perte de qualité ressentie. McKinsey State of AI 2024 identifie ce levier comme premier vecteur de ROI sur les projets matures.
Amélioration de la qualité par routage. Le routage par profil de tâche permet d’utiliser, pour chaque requête, le modèle empiriquement le plus performant. Les scores qualité collectés via Langfuse et Phoenix Arize forment une boucle de rétroaction pour ajuster les règles dans la durée.
Gouvernance et auditabilité renforcées. La politique de souveraineté est appliquée au niveau du routeur : une requête classée sensible n’est pas envoyée à un modèle hors UE. Les traces produisent les éléments de preuve attendus par un audit AI Act, ISO/IEC 42001 ou NIS2. Racine.AI est conçue pour faciliter une démarche de conformité, mais la conformité finale dépend du cas d’usage, du rôle de l’organisation (fournisseur, déployeur, importateur), des données traitées, de la documentation et des procédures internes.
Indépendance technologique. Un changement tarifaire ou contractuel d’un fournisseur ne provoque pas d’interruption applicative : le routeur bascule et le catalogue est mis à jour sans modification du code métier.
4. Cas d’usage représentatifs
4.1 RAG multi-domaines
Une direction juridique, une direction technique et un service client interrogent les mêmes corpus avec des exigences distinctes : citation littérale et traçable pour la juridique, synthèse structurée pour la technique, réponse courte en langage naturel pour le service client. Racine.AI route vers Mistral Large pour la juridique, un Llama finement ajusté pour la technique, et un Phi quantifié pour le service client. Le même corpus indexé dans pgvector sert les trois cas.
4.2 Agents autonomes
Les agents orchestrent plusieurs étapes (planification, recherche, action, vérification) aux profils différents : la planification réclame du raisonnement long (Claude, Mistral Large), l’extraction structurée un modèle JSON mode efficace (GPT, Qwen), la génération de code passe par Codestral, Qwen 2.5 Coder ou DeepSeek selon le langage. Le routeur change de modèle d’une étape à l’autre, ce qu’une stack mono-LLM ne permet pas.
4.3 Benchmarking GEO
Le Generative Engine Optimization (GEO), formalisé par Aggarwal et al., KDD 2024, mesure et améliore la visibilité d’une marque dans les réponses générées par les moteurs IA. La plateforme DataGeo, opérée par TW3 Partners, interroge en parallèle plusieurs LLM (ChatGPT, Claude, Gemini, Mistral, Llama, Qwen) sur un panier de requêtes, mesure la fréquence et la qualité des mentions, identifie les écarts entre moteurs et propose un plan d’optimisation. DataGeo s’inscrit dans cette logique de mesure de visibilité dans les moteurs génératifs, et Racine.AI fournit la couche multi-LLM nécessaire à ce benchmarking croisé.
4.4 Défense et secteur public
Administrations centrales, opérateurs d’importance vitale, acteurs de la défense et industriels manipulant des informations classifiées appliquent des politiques différenciées selon le niveau de sensibilité. Pour les données sensibles non classifiées, un hébergement sur cloud qualifié SecNumCloud (ou cloud souverain équivalent jugé pertinent par l’autorité de tutelle) est généralement attendu. Pour les données classifiées, les exigences relèvent d’environnements dédiés et d’infrastructures propres à l’administration ou au ministère (en France, par exemple, les périmètres opérés par la DIRISI ou l’AMIAD), avec des politiques spécifiques : SecNumCloud ne suffit pas à lui seul à couvrir l’ensemble des usages classifiés. Sur un périmètre classifié, Racine.AI active uniquement le sous-ensemble à poids ouverts du catalogue (Mistral, Llama, Phi, Qwen, DeepSeek), servi via vLLM sur l’infrastructure validée par le client, et interdit toute sortie vers un modèle propriétaire externe.
5. Positionnement modèles ouverts et souveraineté
Intégrer largement les modèles à poids ouverts répond à quatre exigences concrètes.
Auditabilité. Pour de nombreux modèles ouverts, les poids et la documentation sont consultables, parfois accompagnés d’informations sur les données d’entraînement. Le niveau réel d’auditabilité dépend de la licence, des cartes de modèle et de la transparence du fournisseur. Cette information alimente l’analyse de risque attendue par l’AI Act sur les GPAI et par le NIST AI RMF.
Réversibilité. Un modèle à poids disponibles peut être servi sur toute infrastructure compatible. Aucun verrouillage propriétaire n’empêche un changement d’hébergeur ou de fournisseur géré.
Maîtrise du fine-tuning. Les modèles ouverts peuvent être spécialisés sur les corpus de l’organisation avec contrôle complet de la donnée d’entraînement, condition fréquente pour les usages métiers à forte spécialisation (juridique sectoriel, normes techniques, terminologie interne).
Souveraineté économique européenne. L’écosystème français et européen, structuré autour de Mistral AI, Hugging Face et des laboratoires publics, propose une alternative crédible aux fournisseurs nord-américains. La levée de 1,7 Md€ menée par ASML auprès de Mistral en septembre 2025 illustre la capacité du tissu européen à attirer des capitaux industriels stratégiques.
Racine.AI ne rejette pas les modèles propriétaires : ils restent dans le catalogue pour les cas où ils sont objectivement supérieurs. L’architecture rend simplement leur usage facultatif, mesurable et substituable.
6. Méthode TW3 et démonstration VivaTech 2026
La méthode TW3 Partners pour déployer Racine.AI suit cinq étapes : (1) cadrage métier et cartographie des cas d’usage (tâches, volumes, sensibilités, contraintes réglementaires) ; (2) définition du catalogue cible et dimensionnement de l’infrastructure d’inférence (vLLM, Ollama, GPU dédiés ou managés souverains) ; (3) mise en place de la base de connaissances (pgvector, Qdrant ou Weaviate, ingestion, chunking, embeddings, évaluation) ; (4) configuration du routeur (politiques de qualité, coût, latence, souveraineté, fallbacks, budgets par tenant) ; (5) observabilité et amélioration continue via Langfuse, Phoenix Arize et OpenTelemetry.
TW3 Partners présente Racine.AI au salon VivaTech 2026, du 17 au 20 juin 2026, sur le stand Hall 7.2, Allée C, Stand 74. La démonstration inclut un routage multi-LLM en direct sur un cas RAG juridique, une visualisation des traces Langfuse, un benchmark GEO via DataGeo, et une bascule de fournisseur en cas d’indisponibilité simulée. La plateforme DataGeo, accessible depuis tw3partners.fr, permet aux visiteurs de tester le benchmarking GEO sur leur propre marque.
7. FAQ étendue
Qu’est-ce que Racine.AI ?
Racine.AI est l’architecture de référence conçue par TW3 Partners pour orchestrer plusieurs LLM, propriétaires et à poids ouverts, derrière un routeur unique adossé à une base de connaissances souveraine. Elle vise l’optimisation simultanée de la qualité, du coût, de la latence et de la gouvernance des données.
Pourquoi du multi-LLM plutôt qu’un seul modèle puissant ?
Aucun modèle ne domine simultanément l’ensemble des tâches utiles à une organisation. Le Stanford HAI AI Index 2025 et le Hugging Face Open LLM Leaderboard décrivent une fragmentation durable des performances par tâche.
Quel est l’impact financier attendu ?
Le routage par profil de tâche écarte les modèles haut de gamme des requêtes simples. Le rapport coût-performance entre un modèle propriétaire premium et un petit modèle ouvert quantifié servi via vLLM peut varier de plusieurs dizaines de fois selon le modèle, le mode de déploiement et le volume. McKinsey State of AI 2024 identifie ce levier comme principal contributeur au ROI des projets matures.
Racine.AI est-elle conforme à l’AI Act ?
Racine.AI est conçue pour faciliter une démarche de conformité AI Act, NIS2 et ISO/IEC 42001, mais la conformité finale dépend du cas d’usage, du rôle de l’organisation, des données traitées, de la documentation et des procédures internes. L’AI Act est entré en vigueur le 1er août 2024 ; les obligations GPAI sont applicables depuis le 2 août 2025 ; les obligations haut risque s’appliquent progressivement, avec un jalon majeur le 2 août 2026 et des délais étendus pour certains systèmes intégrés à des produits réglementés. Sanctions article 99 : jusqu’à 35 M€ ou 7 % du CA mondial annuel.
Quels modèles figurent dans le catalogue ?
ChatGPT (OpenAI), Claude (Anthropic), Gemini (Google), Copilot (Microsoft), Mistral, Llama (Meta), Phi (Microsoft), Qwen (Alibaba), DeepSeek. Pour la génération de code, Codestral, Qwen 2.5 Coder et les modèles DeepSeek complètent les généralistes.
Quels frameworks open source utilise Racine.AI ?
Orchestration : LangChain ou LlamaIndex. Inférence des modèles ouverts : vLLM et Ollama. Observabilité : Langfuse, Phoenix Arize, OpenTelemetry. Bases vectorielles : pgvector, Qdrant, Weaviate. Tous ces composants sont open source.
Comment la souveraineté est-elle garantie en pratique ?
Une requête classée sensible ne sort pas du périmètre d’hébergement qualifié défini par le client. Pour les usages les plus exigeants, seul le sous-ensemble à poids ouverts du catalogue est activé, sur infrastructure SecNumCloud, cloud souverain équivalent, ou environnement dédié selon le niveau de classification.
Quelle place pour le GEO dans Racine.AI ?
Le GEO (Aggarwal et al., KDD 2024) nécessite d’interroger plusieurs moteurs IA en parallèle pour mesurer la visibilité d’une marque. Cette mécanique est nativement supportée par l’architecture multi-LLM de Racine.AI et opérationnalisée par DataGeo.
Quelles différences avec une simple intégration multi-API ?
Une intégration multi-API expose plusieurs fournisseurs via une façade. Racine.AI ajoute un routeur décisionnel par requête, une politique de souveraineté contraignante, un catalogue gouverné, une base de connaissances unifiée et une observabilité par appel : quatre couches supplémentaires nécessaires à une exploitation en production gouvernable.
Racine.AI fonctionne-t-elle dans un environnement on-premise strict ?
Oui. Le sous-ensemble à poids ouverts du catalogue (Mistral, Llama, Phi, Qwen, DeepSeek, Codestral, Qwen 2.5 Coder) peut être déployé entièrement on-premise via vLLM ou Ollama, avec pgvector ou Qdrant pour la base vectorielle, et OpenTelemetry pour l’observabilité. L’architecture peut être configurée sans appel sortant lorsque le contexte client l’exige.
8. Sources
Stanford HAI, AI Index Report 2025 : https://aiindex.stanford.edu/report/
Hugging Face, Open LLM Leaderboard : https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
McKinsey, The State of AI 2024 : https://www.mckinsey.com
Union européenne, Règlement 2024/1689 (AI Act) : https://eur-lex.europa.eu/eli/reg/2024/1689/oj
Commission européenne, AI Act et calendrier de mise en application : https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai
NIST AI Risk Management Framework 1.0 : https://www.nist.gov/itl/ai-risk-management-framework
Commission européenne, Directive NIS2 : https://digital-strategy.ec.europa.eu/en/policies/nis2-directive
Aggarwal et al., GEO: Generative Engine Optimization, KDD 2024 : https://dl.acm.org/doi/10.1145/3637528.3671900
Mistral AI, levée de 1,7 Md€ menée par ASML, septembre 2025 : https://mistral.ai/news/mistral-ai-raises-1-7-b-to-accelerate-technological-progress-with-ai
TW3 Partners et plateforme DataGeo : https://tw3partners.fr
